
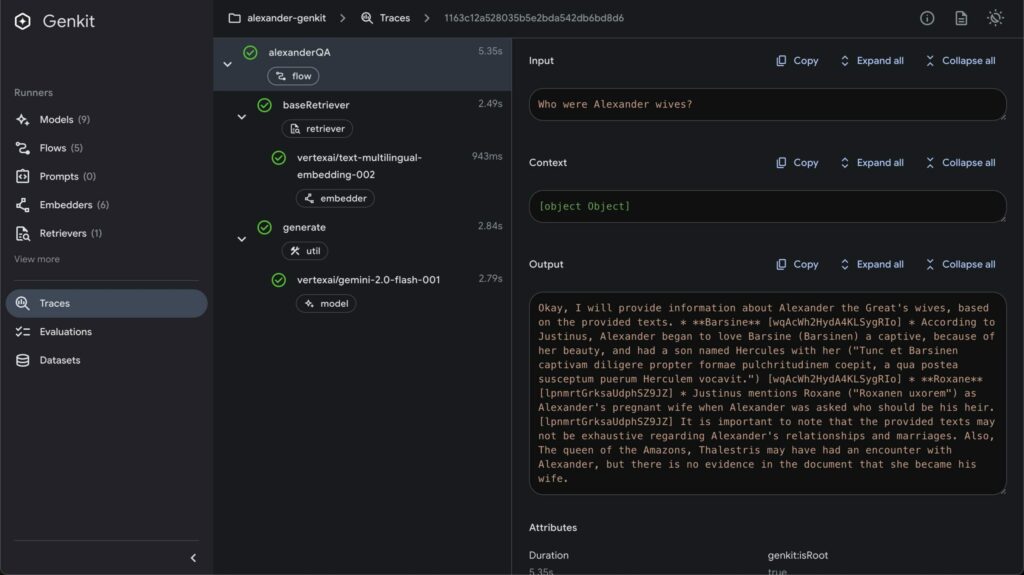
I am currently working on an ambitious project that involves performing RAG on Ancient Greek text.
RAG stands for Retrieval Augmented Generation. It’s designed to solve a recurring problem with LLMs: the gaps in their knowledge base and their limited context. Even though these contexts have already improved—with Google Gemini’s 1M tokens—it’s barely enough to compare two different versions of the Bible. This process retrieves the needed documents using semantic queries before feeding them to your prompt to augment it.
For this project, I’m using GCP Vertex AI, Genkit, and Firebase with Node TypeScript.
Firebase is an array of cloud services that include database, authentication, AI, and other tools. Genkit is Google’s framework that allows you to code, perform, and chain numerous AI operations, calling different AI models, vector databases, and enabling agentic behavior. This framework can be executed in a local UI, greatly simplifying development by providing the results of each method in the chain of actions. Vertex AI is a collection of GCP services specialized in AI.
When I first saw RAG tutorials, I was hoping to make it work in one week. It took me more than a month. Here is an important extract of the text (shown here in English) I wanted to experiment with:
[359d] which men say once came to the ancestor of Gyges the Lydian. They relate that he was a shepherd in the service of the ruler at that time of Lydia, and that after a great deluge of rain and an earthquake the ground opened and a chasm appeared in the place where he was pasturing; and they say that he saw and wondered and went down into the chasm; and the story goes that he beheld other marvels there and a hollow bronze horse with little doors, and that he peeped in and saw a corpse within, as it seemed, of more than mortal stature,
[359e] and that there was nothing else but a gold ring on its hand, which he took off and went forth. And when the shepherds held their customary assembly to make their monthly report to the king about the flocks, he also attended wearing the ring. So as he sat there it chanced that he turned the collet of the ring towards himself, towards the inner part of his hand, and when this took place they say that he became invisible
[360a] to those who sat by him and they spoke of him as absent and that he was amazed, and again fumbling with the ring turned the collet outwards and so became visible. On noting this he experimented with the ring to see if it possessed this virtue, and he found the result to be that when he turned the collet inwards he became invisible, and when outwards visible; and becoming aware of this, he immediately managed things so that he became one of the messengers
[the story continues for 3 paragraphs]
The Technical Foundation
To perform RAG, your documents need to be chunked using the “llm-chunk” npm library. This process breaks your text into smaller pieces, making them ready for vectorization. The vectorization process stores the text in semantic form, capturing the meaning of words put together. It’s important to note that this vectorization is performed by third-party cloud services, which means the amount of chunks you can vectorize in one request is limited—you can hardly go beyond vectorizing more than 700 KB of text in a single request.
To store these vectorized texts, you need a vector database. I chose Firestore because I’m a Firebase enthusiast, but Supabase and even Quadrant also offer vector databases.
The First Challenge: Language Models
Here comes my first problem: the Genkit RAG tutorial recommended using ‘text-embedding-005’. My initial tests on English text were going great, until I tried to search for the story of Gyges in the Greek version of Plato’s Republic. It was impossible to get any valuable information from the RAG process. This is because non-Latin text requires a special embedding model—textMultilingualEmbedding002—that enables RAG on Greek, Hindi, Russian, Japanese, Arabic, and tons of other languages.
[Reference: https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/text-embeddings-api?hl=fr]
The Second Challenge: Narrative Coherence
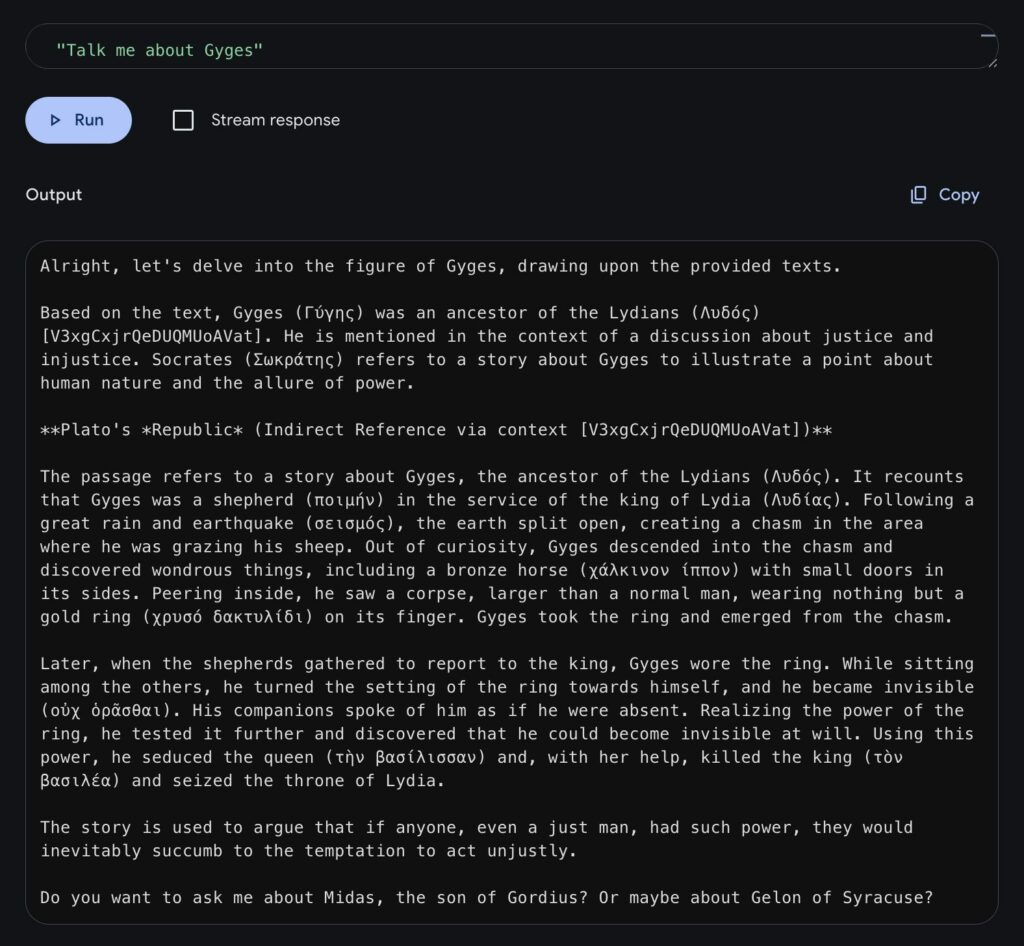
Great! I got Gyges working. But now I had another problem: Gyges is only mentioned once in Plato’s Republic, but his story spans four paragraphs and ends up split across multiple chunks that won’t be retrieved during semantic search. This means you end up with only part of Gyges’ story, not the complete narrative.
Chunking takes configuration parameters to increase chunk size and overlap between chunks. A website like ChunkViz (https://chunkviz.up.railway.app/) helps you preview what different chunk lengths and overlaps will look like. However, in my case, increasing the overlap to even 400 characters wasn’t sufficient—I needed at least 10 times that size.
One workaround would have been creating a second request to query all documents adjacent to the retrieved ones. That would have worked, but I found a far more innovative method that opens up infinite possibilities.

The Creative Solution
Compromise is a JavaScript NLP (Natural Language Processing) library that extracts names and places from texts (along with verbs and adjectives). While running your RAG pipeline, you can simultaneously populate an entire database of places and characters. Of course, getting Compromise to work on Greek text wasn’t easy, but thanks to a suggestion from Claude, I created a Greek-to-Latin alphabet conversion table. This allowed me to romanize names while preserving letter case, which finally enabled Compromise to extract the famous Γύγης (Gyges).
The final step was adding the names and places cited in the last four paragraphs to each text segment before vectorization. Thanks to this method, I was able to retrieve the complete story of Gyges from Plato’s Republic in one request.
Beyond the Basics
RAG is complex, and this post only scratches the surface. RAG can implement metadata and rerankers—it all depends on your use case and the problem you want to solve. In my upcoming Alexander the Great project, I have to deal with an incredible number of sources, each with its own opinion about what really happened. I use reranking to ensure that responses to questions are diverse enough, countering RAG’s natural tendency to always retrieve the same author due to their more concise writing style.
[Reference: https://genkit.dev/docs/rag/]
Conclusion
This post ends here, but not my newsletter—it’s where I plan to share my best work about Classical Education and AI, completely free. I have the conviction that both subjects are linked. If you’re not already a subscriber, you should be, because both Classical Education and AI represent precious knowledge right now.